BigQuery MLで商品一覧画面の並び順を改善して売上を40%上げた話

目次
- はじめに
- 基本設計
- フェーズ1: とりあえずAutoMLを使ってみる
- フェーズ2: 目的変数を変える
- フェーズ3: BigQuery MLの導入による検証高速化
- フェーズ4: 国別
- フェーズ5: 回帰ではなく分類へ
- フェーズ6とその先へ
- おわりに
はじめに
自己紹介
じげん開発Unitデータ分析基盤チームの伊崎です。
開発Unitは特定の事業部に所属しない全社横断組織です。
その中で、データ分析基盤チームは全社のデータ基盤の整備、データ利活用を担当しています。
私個人としては、大学で純粋数学を学んだ後、前職でエントリーレベルの機械学習エンジニアとして働きました。現職では半分データエンジニア、半分データサイエンティストとして働いています。
プライベートでKaggleに参加し、銅メダルを獲得した経験があります(最近は活動できていませんが…)。
Twitterアカウント
Kaggleアカウント
内容概要
本稿では、BigQuery MLを利用した機械学習施策により、じげんの海外向け中古車輸出プラットフォームであるTCVの売上を40%増加させた事例を紹介します。
非常に簡易なシステムとなっているので、特に機械学習を未導入の方の参考になるかと思います。
また、導入済みの方にも、BigQuery MLの利点を感じていただくとともに、試行錯誤の過程を楽しんでいただければ(そしておかしなところがあればご指摘いただければ)と思います。
基本設計
TCVのビジネスモデル
TCVは、海外のユーザーに中古車を売りたい日本の販売店と、日本の中古車を購入したい海外のユーザーをつなぐサービスです。
整理すると、TCVにはステークホルダーが2つ存在します。
- セラー: 中古車をTCVに出品する日本の販売店
- バイヤー: TCVのサイトを訪れて中古車を購入する海外のユーザー

サイトを介してバイヤーが中古車を購入したタイミングで、TCVはセラーから仲介手数料を受け取ります。
これがTCVにとっての売上となります。
施策内容
TCVの在庫検索画面(バイヤーが中古車を探す商品一覧画面)では、価格順、製造年順などの並び替えができます。
ここに、新たに「おすすめ順(Featured)」を導入し、そこを経由した購入を促すというのが施策の内容です。これにより購入数と単価を向上させ、売上を増やすことを狙います。
システム構成
下記がシステムの全体像です。
機械学習により、事前に在庫ごとのスコアを計算しておき、Solrに格納しておきます。
おすすめ順を表示する際はこのスコアの順に並べます。
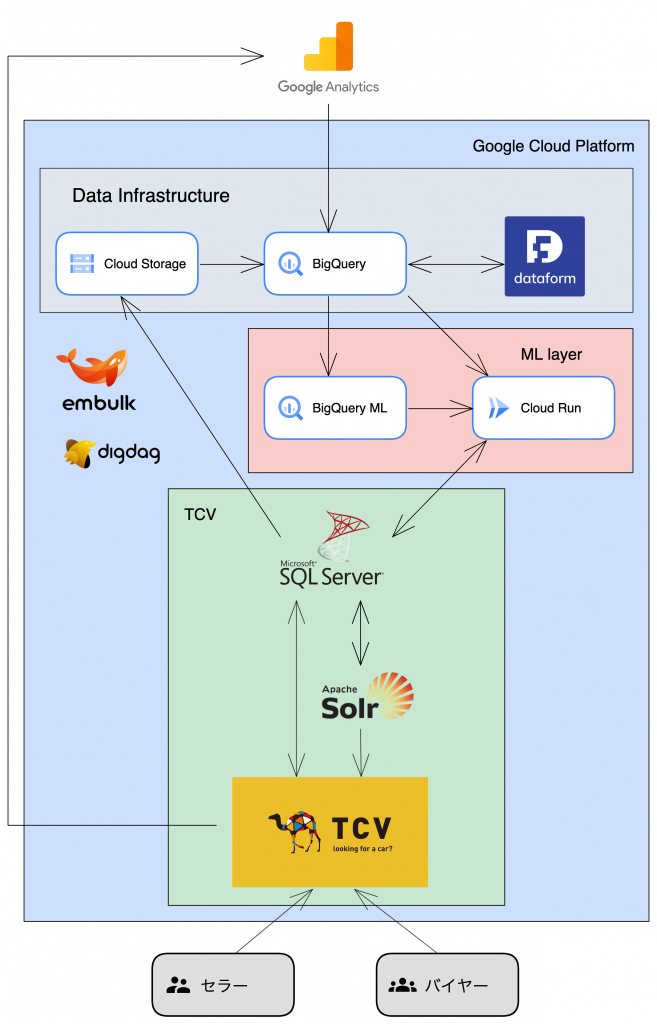
学習手順
まず、必要なデータが3つあります。
- バイヤーの在庫詳細ページ閲覧履歴データ(GAから取得)
- 在庫のデータ(価格、車種など)(SQL Serverから取得)
- バイヤーの購買データ(SQL Serverから取得)
これらを、全てBigQueryに集約します。
そのデータからBigQuery MLにより手動でモデルを作成し、手動でExportしてCloud Runにデプロイします。
推論手順
セラーが新しい在庫をアップロードするごとに、TCVのシステム側からCloud Runにアクセスし、得られたスコアをSQL Server経由でSolrに保存します。
モデルは手動デプロイですが、定期的に更新が必要な特徴量はDataformで更新してBigQueryに入れており、推論の際に参照します。
フェーズ1: とりあえずAutoMLを使ってみる
経緯
じげんが運営する、国内向け中古車ポータルサイトの中古車EXでAutoMLとCloud Runによるおすすめ順表示を行っています。
まずはそれをそのままTCVにスライドさせる、というところから始めました。
この時点ではまだBigQury MLは使っていません。
手法
中古車EXとTCVは以下の図のように、マネタイズポイントが異なります。
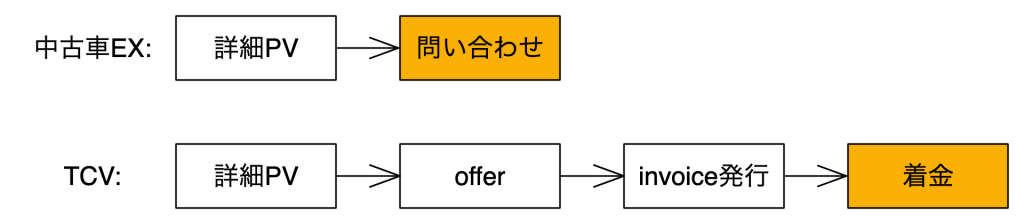
中古車EXでは、在庫ごとの詳細画面でのCVR(問い合わせ数 / 詳細PV数)が高い順をおすすめ順としています。
TCVでは
- 着金(バイヤーが実際に代金を振り込むタイミング)に至って初めて手数料収入が得られる
- 在庫によりセラーから得られる手数料単価が異なる
上記のことから、在庫ごとの予想invoice率(invoice数 / 詳細PV数) × 単価の順を、おすすめ順として並べることとしました(以下、PV数 = 詳細PV数とします)。
予測対象を着金率(着金数 / PV数)としなかったのは、PV数に対して着金数が非常に少なく、学習が難しかったためです。
あとは、特徴量をできるだけたくさん用意し、AutoMLで学習を行いました。
結果
ABテストを行い、invoice数は有意に増加しましたが、着金数が減少したため、導入見合わせとなりました。
考察
やはり着金まで追わないと着金数は増えない、という結論に至りました。
フェーズ2: 目的変数を変える
経緯
フェーズ1を踏まえて、着金率(着金数 / PV数)を最適化する方向に舵を切りました。
手法
素直に目的変数を着金率にしました。
結果
ABテストの結果、売上が大きく落ちてしまいました。
考察
そもそも、単純に予測精度が悪すぎました。
並び順を人の目で確認しても、明らかにおかしな順序がみられました。
フェーズ3: BigQuery MLの導入による検証高速化
経緯
予測精度を上げるため、トライアンドエラーを繰り返すことが必要だと考えました。
AutoMLはそれなりの時間(最低でも数時間)と費用(最低でも$21.252)がかかります。
したがって、AutoMLは最終的なモデルを得るためのみに用い、そこまでの試行錯誤は普通のGBDTでやりたいと考えました。
そこで、BigQuery MLを用いることにしました。
手法
BigQuery MLを以下のように使っています。
- BigQueryで特徴量作成
- BigQuery MLのGBDTモデルでモデル作成、精度検証
- 特徴量生成&モデル作成クエリをGit管理
- 最終的なモデル作成はBigQuery MLのAutoMLモデルを利用
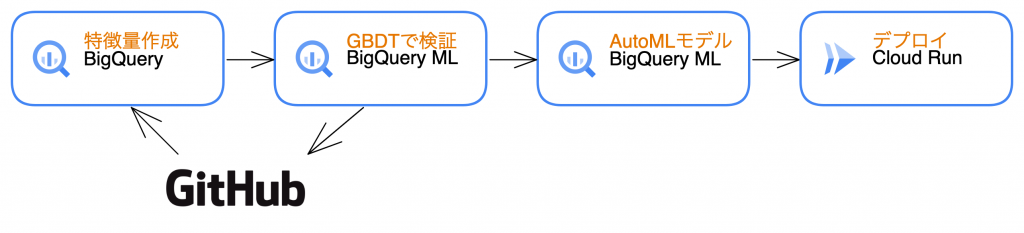
これにより、高速で検証を進められるようになりました。
この過程で、着金率予測(着金数 / PV数)を、offer率予測(offer数 / PV数)と着金率予測(着金数 / offer数)に分離する手法を発見しました。
というのも、両者で使うべき特徴量が大きく異なっていたからです。
TCVのビジネスに詳しいマーケターとセールスの力を借りつつ、効きそうな特徴量を導入し、逆に効かないものを省いてモデルをスリムにし(スコアリングの高速化のため、非常に重要でした)、急ピッチでモデルの改善を行いました。
このころ粋がって行ったTwitter投稿です。

結果
10%の売上向上が達成できました。ただし、国によって良し悪しが大きく分かれます。具体的には、TCVの最大市場であるアフリカの主要国では伸長しましたが、その他ではうまく行かなかったのです。
これを踏まえて、アフリカの主要国のみでの導入を決め、次のフェーズへの移行となりました。
考察
国によって、売れる車種は異なります。また、国によっては製造後何年経っていないと輸入できない、などの法制度もあります。アフリカでは基本的にトヨタ車が売れますが、そこに学習が偏ってしまうと、北米やヨーロッパでは売れません。これが生じていると考えました。
フェーズ4: 国別
経緯
フェーズ3の、国ごとに売れる在庫が異なるという反省点を踏まえて、国による違いを学習に取り入れる方針を立てました。
手法
在庫に国別のスコアを保持させておき、サイトに訪れたバイヤーのIPの国を元に出し分けを行う、という手法を取りました。
売買の現場をよく知るセールスにアドバイスをもらい、よく売れる車種や法制度をベースに全世界を9グループに分けました。初めはそれぞれのデータで学習を行いましたが、データ量が足りなかったため、最終的にそれぞれのグループの要約統計量を特徴量として用いる、というところに落ち着きました。
結果
うまくは行きませんでした。アフリカ、それ以外の地域ともに主要国での売上が減少しました。
考察
今回の狙いからして、主要国の売上が落ちることは想定外でした。
特に落ちていたのはoffer数(バイヤーの問い合わせ数)です。
仮説として考えたのは、学習自体は非常にうまく行っていたが、「着金率」が目標変数として適切でなかったために、バイヤーの反応がかえって悪化してしまった、というものです。
着金率の定義は以下の通りです。
これが、主要国でoffer数が減少した原因だと考えました。
フェーズ5: 回帰ではなく分類へ
経緯
フェーズ4の反省を踏まえて、着金率を予測する回帰問題ではなく、その在庫が着金したものかどうか(予測の文脈では、着金するかどうか)の分類問題を解くことにしました。
これにより、offer数に対するペナルティを回避できます。
手法
最終的に、並び順は以下の式のスコアの降順にしています。
結果
フェーズ3の並び順とのABテスト中で、アフリカ以外も含めて主要国を中心に売上が増え、全体で40%を超える売上増となりました。
ただし、主要国以外(オセアニア、カリブなど)では売上の落ち込みが見られます。
考察
国別の学習の効果が素直に反映されたと考えています。主要国以外でうまく行かなかったのは、データ量が足りないため想定の範囲内です。
フェーズ6とその先へ
フェーズ6として、主要国以外でも結果が得られるよう、バイヤーのデータを国以外にも取り入れて複合的なグループを作成し、どのグループも一定のデータ量を持つようにすることを検討しています。
国以外のデータとしては、バイヤーが閲覧した車種データなどを考えています。
グルーピングはBigQuery MLで作成した特徴量によるクラスタリングと、人の目を組み合わせて作る予定です。
また、ここまでの内容では、全て事前にスコアリングを行っており、バイヤーの行動に対するリアルタイムなスコア生成は行っていません。
フェーズ6のグルーピングによりバイヤーの行動への理解を深めた延長として、リアルタイムスコアリングにも着手していきたいと考えています。
おわりに
振り返ってやはりゲームチェンジとなったのは、BigQuery MLの導入により高速でPDCAを回せるようになったタイミングだと考えています。
エンジニアで閉じずに広くビジネスサイドの意見を取り入れられるようになったのもこのタイミングでした。
教師データがBigQueryにあり、特別なモデルを必要としない場合、特徴量生成から最終的なアウトプットまで一気通貫でこなせるBigQuery MLは、有力な選択肢となると思います。
また、ここで紹介した手法は、そのままじげんの別のサービスに横展開を行っています。
ある程度型が決まってくれば、データにそれほど詳しくないメンバーにも扱えるようになるとみています。
その意味でも、なるべくSQLだけで完結するシンプルな設計を目指しています。
じげんでは、これからもエンジニア、マーケター、セールス一丸となってデータを元にビジネスをしていきます。
このような環境で働きたい皆様をお待ちしています。